I will be at https://www.mendrugory.com
|
Data Scientist is considered the sexiest job around the world, at least in the tech world, and it is true that sometimes the results that you can get applying Machine Learning techniques seem to be sorcery. Therefore a lot of people are trying to become data scientist.
A lot of them use Python and almost all the on-line courses use also Python to teach the concepts.
Python is a lovely programming language. It is so easy to get into and the final code is, sometimes, even beautiful. But all these things mean nothing when you face the GIL. There some solutions like multiprocessing. It is good when you can split the data in big chunks. Other approaches are related to apply horizontal scaling techniques in order to get a vertical scaling, what does it mean? If you have read about the GIL you already know that Python will only take advantage of one CPU core of your PC so, why don't we launch more Pythons and let's split the load between them using load balancing, messaging systems, and so on?
You can see that the first example is prepared to scale-in and the second one to scale-out. But all of them seem to be too much for a guy who only wants to develop a "Python code" so let's back to the data science world.
Typing an algorithm in Python is a pleasure and the ecosystem is great. Libraries like numpy or scipy will help you a lot. But you can also find higher-level libraries like scikit-learn or tensorflow. So, how am I not going to use Python for Machine Learning?
Some weeks ago I spend some time watching videos and presentations about Erlang and I remembered two things:
Why don't I try to handle my Python code using Elixir? In this way I will be able to scale and specially to add fault tolerance.
With these things in mi mind I began to code Piton which is a library that uses Erlang Ports, thanks to ErlPort, to directly communicate Elixir and Python.
The first step is to have a Python project. I am going to use a simple example of a Fibonnaci calculator. def fib(n): if n < 0: raise Exception("No negative values !!!") if n == 0: return 0 if n < 3: return 1 return fib(n - 1) + fib(n - 2)
Then, create the module of your own Port using Piton.Port:
defmodule MyPoolPort do use Piton.Port def start(), do: MyPoolPort.start([path: Path.expand("python_folder"), python: "python"], []) def fun(pid, n), do: MyPoolPort.execute(pid, :functions, :fun, [n]) end
It is mandatory to have a start() function which provides the path to the python project and the python interpreter which could belong to a virtual environment. Then you can define as many function as you need. I recommend to create some wrappers for the execute() function which only needs the pid of the process which is connected to one Python, the atom of the python module, the atom of the python function and a list of arguments for the python function.
Now we only have to launch our Piton.Pool, indicating which module is going to use and the number Pythons we want to run, and use it: iex> {:ok, pool} = Piton.Pool.start_link([module: MyPoolPort, pool_number: 2], []) {:ok, #PID<0.176.0>} iex> Piton.Pool.execute(pool, :fib, [20]) 6765
Two months ago I published in hex the first version of Galena, a Topic producer-consumer library built on top of GenStage for Elixir. It was initially designed to create some flows of producers, producer-consumers and consumers where the message has to be delivered as soon as possible. Each consumer or producer-consumer can receive messages from several producers and/or producer-consumers. Besides, consumers and producer-consumers can select the messages that want to receive thanks to a topic approach.
This library was thought to be used by an application which will run in a server but, why don't we try to distribute the Galena's producers, producer-consumers, consumers to several machines? Elixir code runs in the Erlang Virtual Machine or BEAM and therefore it can take advantage of all its distribution features. Erlang provides the module global which helps us to registry the name of the process globally. It means that we can interact with any globally registered process after connecting the nodes. Taking into account these ideas we can use Galena as a distributed producer-consumer system: iex(test1@machine1)> MyProducer.start_link([], [name: {:global, :producer}] iex(test2@machine2)> MyConsumer.start_link([producers_info: [{["topic"], {:global, :producer}}]], [name: {:global, :consumer}])
Life is a succession of asynchronous events which could depend on each other.
Some weeks ago my friends and I wanted to play a football match, therefore we booked a football pitch of a sport centre for the next Saturday at 17pm. On that Saturday, I arrived to the sport centre at 16:44 and other guys were already there and they had arrived between 16:31 and 16:42. Five minutes later arrived more people. At 16:50 only three people were not there, we were 19 and and we needed 22 in order to enjoy a proper football match. We called them but only one was contacted and he arrived 3 minutes later. At 17:00 we were 20 people and we decided to wait 5 minutes more before beginning the football match. They did not arrive and we began to play a football match with teams of 10 people. As you can see, the football match is an event that depends on other events like booking the football pitch or people arriving. When the event has to be processed, you have already checked all your dependencies, if not, you can wait or try to get them. Finally you can perform the event, cancel it or adapt it. Streaming Data
Nowadays I have been dealing with a new problem: Working with a streaming of data where the received messages could have relation between them. When I work with a stream of data and my chosen language has been Elixir, I try to take advantage of the concurrency offered by the Erlang Virtual Machine. That approach help me to parallelize as much as possible improving the performance but also other challenges are introduced, for instance, the data is not ordered, hence; trying to process messages in concurrent flows, could increase the difficulties.
Meanwhile I was reading Designing for Scalability with Erlang/OTP and it explains how the synchronous and asynchronous calls to a gen_server are implemented. It gave me an idea. If I am going to process each received event in a different process, why don't I check/request its dependencies and the process will wait for a message with:
Conductor for our orchestra of processes
Barenboim is a OTP application which will help you with this task.
In the process where the received event is being processed, define how to check/request your dependency and call the function get_data() of Barenboim module. fun = fn(dependency_ref) -> MyDataModule.get(dependency_ref) end {:ok, data} = Barenboim.get_data(dependency_ref, fun)
The checking phase will be executed in the same process, but if the dependency is not available yet, the process will wait for a message from Barenboim which will send the dependency when this one is ready.
Meanwhile, another process receives the wanted event and process it. When this event is processed, this process has to notify to Barenboim that the event is ready. # Only the reference Barenboim.notify({:reference, dependency_ref}) # Or the data Barenboim.notify({:data, dependency_ref, dependency_data})
I highly recommend to pass a time out to the function get_data(), if not, it will wait forever (maybe it fits your needs because you are very sure that all the events will arrive). In that case, you can receive a time out message:
case Barenboim.get_data(dependency_ref, fun, 5_000) do {:ok, data} -> # go on {:timeout, any} -> # decide what you can do end
This week I have released my two first contributions to the elixir open source community in hex: Galena and Conejo.
Galena is a library based on GenStage that will help you to create your topic producer-consumer data pipelines. Conejo is an OTP application/library that facilitate the creation of publishers and consumers of RabbitMQ or AMQP servers. It is based on the library amqp.
I am very surprised that most of the questions that I have received are about the tests:
"How do you test the libraries if they provide Behaviours to develop concurrent apps?" Let's see how. Testing
Elixir has a really good unit test framework, ExUnit, which is really easy to use. Otherwise we are talking about concurrent apps, where more of the logic will be executed in different processes, because we want to scale and Elixir allows you to do it, and ExUnit will only pass a test if the assert function is in the main process.
As we have already mentioned we are using Elixir and we use the Actor Model, therefore we can send messages between the processes. Let's see how to use it for testing.
Register the main Process
The first step is to register the process where the test is running: test "receive message" do Process.register(self(), :main_process) ...
Send the message with the result to the Main Process
The callback which will handle the message in the secondary process, has to send the result to the main process. ... def handle_message(message) do result = do_work(message) send(:main_process, result) ... end ...
Check the result in the Main Process
Finally we have to check the result in the main process. Sometimes, we are only interested in knowing that the message was processed by the secondary process and sent to the main one: # Main Process ... Logger.info("Waiting for the message ...") assert_receive(message, timeout)
But in other cases we also want to check that the secondary process executed its transformation well. (Assuming that the message is a tuple with a topic and a result)
# Main Process ... receive do {topic, result} -> assert topic == expected_topic assert result == expected_result msg -> assert false end 
Currently I am working in a project where I have to integrate many real-time data sources and show the results to the users as soon as possible. As you can imagine Elixir + PhoenixFramework are my chosen tools. This kind of projects always imply a lot of challenges that we have to solved (check my fork of Floki). But the tedious one has not been directly related with the particular case of this project, it has been dealing with Brunch. Brunch is a front-end build tool that is brought by Phoenix by default. It seems to be simple (especially if you compare with Webpack), but my problems began when I need to execute different Javascript scripts depending on the rendered Phoenix template.

The HTML from Phoenix are rendered in server side and Brunch compiles and joins everything (by default) to one Javascript file(or maybe two if you want to have the 3rd party in other place). That provokes that you will have an unique entry point, but if you will have several "views" already rendered from the server, maybe you will have several needs that will be covered by different Javascript codes and you don't want to execute always all.
¿How did I finally solve it?
Brunch can compile and join the Javascript files in the way that you decide, therefore I decided to create two main folders inside web/static/js path:
We will say to brunch that it has to produce a common.js file for all the javascript files that are not in "specific" folder (common + 3rd party) and one file per template that will be under "specific" folder (I created a folder per template because it was better for my sanity where the js file and the folder have the same name. Maybe in the future you have to have more specific logic in each template and you need to have more js files in each folder). I know that I will finally produce more files that we would have desired, but the heaviest part should be in common.js, and each entry point Javascript file will contain a few lines of code (in my case, less than 10 lines each) because we only need to use these files for initializations. exports.config = { files: { javascripts: { joinTo: { "js/common.js": /(?!web\/static\/js\/specific)/, "js/myscript.js": /^(web\/static\/js\/specific\/one)/, "js/myscript2.js": /^(web\/static\/js\/specific\/two)/, "js/myscript3.js": /^(web\/static\/js\/specific\/three)/ } ... }
All the Phoenix templates are rendered using a layout (web/static/templates/layout/app.html.eex). This file assumes that Brunch is going to produce a Javascript file called app.js which will contain all the logic that we need and also the entry point. In our case, we have to substitute this file by common.js because this new file will contain all the logic. And then, we have to add two new lines:
<script type="text/javascript" src="<%= static_path(@conn, "/your_app/js/common.js") %>"></script> <script type="text/javascript" src="<%= static_path(@conn, "/your_app/js/" <> assigns[:js_script]) <> ".js" %>"></script> <script>require("<%= "web/static/js/specific/" <> assigns[:js_script] <> "/" <> assigns[:js_script] %>")</script>
The first one will indicate the necessary Javascript file in each case and the second one will indicate that it is the entry point, so it will be executed.
As you can see, we have used the possibility of reading custom values that could be stored in the user connection, hence; we only have to indicate in the variable ":js_script" which one should be used in each case. defmodule YourApp.YourController do use YourApp.Web, :controller def index(conn, _params) do conn |> assign(:js_script, "my_script") |> render("index.html") end end
The main logic and the 3rd party code which are the heaviest part will be in common.js, so it will be downloaded once and cached by the browser and the specific parts, just your few lines of initialization, will be downloaded for each template, although it will finally be cached as well.
This method was the simplest one that I found in order to solve my problems, I hope that it is useful for someone else. 
I like a lot RabbitMQ. It is a really good system when you have to work with events and build your systems with asynchrony in mind. Although silver bullets do not exist in the SW world, when you require a complex routing, scalability and reliability, RabbitMQ is your system.

I usually work in a polyglot environment, but when one of the systems has to deal with a lot of connections (i.e. Message Queue Systems, Databases, Web Servers, ...) Elixir is my choice. And when I have to deal with RabbitMQ I use a wonderful library, pma/amqp.
When we code several projects that involve the same language and the interaction with the same system, we always have to build the same code base. In this case, a connection to RabbitMQ and the different channels with their own callbacks. The only difference between the code which manages the channels are the callabacks; therefore I decided to create a OTP application which will always take care of this common code, the name -> Conejo (Rabbit in Spanish).
I began creating a module which will take care of the RabbitMQ connection (only one tcp connection per project, if you have more "connections" use the channels). This module will be a GenServer which will be supervise by a Supervisor.
Once that I had the connection, I decide to create some Behaviours which will decrease the complexity of working with RabbitMQ: Conejo.Consumer and Conejo.Publisher. Both of them are based on GenServer. If you want to use the first one, you will only implement a function consume(channel, tag, redelivered, payload) and if you use the second one, you don't need to implement any code on your module to make it work.
defmodule MyApplication.MyConsumer do use Conejo.Consumer def consume(_channel, _tag, _redelivered, payload) do IO.puts "Received -> #{inspect payload}" end end options = Application.get_all_env(:my_application)[:consumer] {:ok, consumer} = MyApplication.MyConsumer.start_link(options, [name: :consumer]) defmodule MyApplication.MyPublisher do use Conejo.Publisher end {:ok, publisher} = MyApplication.MyPublisher.start_link([], [name: :publisher]) #Synchronous MyApplication.MyPublisher.sync_publish(:publisher, "my_exchange", "example", "Hola") #Asynchronous MyApplication.MyPublisher.async_publish(:publisher, "my_exchange", "example", "Adios")
Previously, you have to define the configurations for the conejo connection (mandatory) and your channels (if you want). Conejo respects the configuration of pma/amqp. For example:
config :my_application, :consumer, exchange: "my_exchange", exchange_type: "topic", queue_name: "my_queue", queue_declaration_options: [{:auto_delete, true}, {:exclusive, true}], queue_bind_options: [routing_key: "example"], consume_options: [no_ack: true] config :conejo, host: "my_host", port: 5672, username: "user", password: "pass"
As you can see, really easy.
Add to your project and begin to use it :D
# mix.exs def deps do [{:conejo, git: "https://github.com/mendrugory/conejo.git"}] # or [{:conejo, "~> 0.1.0"}] when is available end def application do [applications: [:conejo]] end
Check it in Github.

Scala is a general purpose programming language that compiles to Java bytecode, therefore, it will run on the JVM. You can code is Scala using an object-oriented approach or a functional approach but almost everybody who codes in Scala tries to do it using the second one. But, why?
You only need to search on Google and you will find the benefits that are told for many people about immutability like: Thread Safe, Concurrency, Scalability, Maintainability, Performance and many more.
This post will not try to explain these benefits or even to convince you about the immutability. It will only try to perform a very easy coding test. I will try to solve a project-euler's problem using both approaches, specifically, the problem 2.
Even Fibonacci numbers
Code:
object Problem2 { def main(args: Array[String]): Unit = { println("Project Euler 2\n") val number: Int = 4000000 println("Mutability Result: \t" + time({mutable(number)}, "Mutability Time: \t")) println() println("Immutability Result: \t" + time({immutable(number)}, "Immutability Result: \t")) } def time[R](block: => R, introMessage:String): R = { val t0 = System.nanoTime() val result = block val t1 = System.nanoTime() println(introMessage + (t1 - t0) + "ns") result } def mutable(number: Int): Int = { var (first, second, acc) = (1, 2, 2) while (second < number) { val aux = second second += first first = aux if (second % 2 == 0) acc += second } acc } def immutable(number: Int): Int = { immutableFib(1, 2, number, 2) } def immutableFib(first: Int, second: Int, number: Int, acc: Int): Int = { second match { case _ if second < number => val next = first + second val newAcc = if (next % 2 == 0) acc + next else acc immutableFib(second, next, number, newAcc) case _ => acc } } }
Results:
Project Euler 2 Mutability Time: 1506573ns Mutability Result: 4613732 Immutability Time: 25331ns Immutability Result: 4613732
Note: Without the time wrapper, measuring directly the elapsed time, the results are much better.
Although the two algorithms obtain the same result (All roads lead to Rome) you can see which kind of code will be more maintainable, will work better when you build concurrent systems and will perform better.
It is true that coding in a functional way is not easy, especially when the language has not been designed to do it, but in Scala you can choose the way, therefore, it is up to you.
 Since I discovered the couple Mesos - Marathon, I always try to use them to put my projects on production. They provide web interfaces where you can check your apps, a very easy REST API in order to interact with the apps, an easy way of managing the resources of your cluster and the most important part for me, High Availability. Marathon provides support for Docker containers what is a wonderful piece of news. Currently everything to me is a container. If you launch a Docker container using the cmd command of Marathon, the tool will be able to launch the app and it will be able to tracked as well but you will not be able to switch down from Marathon. This tech stack is amazing if your project is micro-services oriented. You will launch independent apps that are packaged in Docker images through Marathon. So far, it seems to be a perfect scenario, but Mesos will execute your apps in one server of your cluster (or some, depending on the instances that you have launched) that you will not know at the beginning. If one app don't know where is running another app that it needs to request data to process it, how is it going to work? We have a bunch of blind apps. We have to add an auto-discovery system. You can find several options, I like to use Mesos-DNS. This tool is a classical DNS but it asks to Mesos which apps are running on it, so through this DNS all the apps will know where the other apps are. One important thing will be how the app will be named because you won't have an IP or host name, you will have an app name: <the name of the app that is the id of marathon>.marathon.mesos. 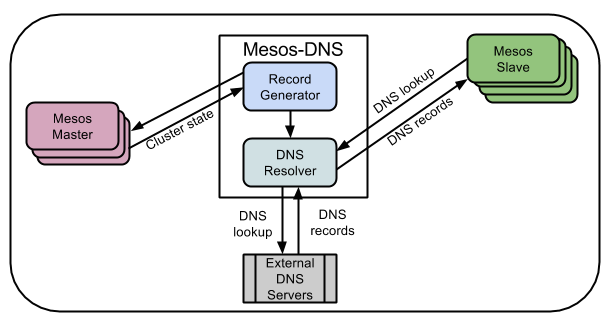 Mesos-DNS will be another app launched through Marathon. You can find several docker images in Docker Hub. I like tobilg/mesos-dns. Now, we only have to add the DNS to all the Docker containers of our apps. And here I found a lot of problems. The network configuration has to be HOST if we want DNS-mesos works, something that is not compatible with adding a DNS through the Docker support of Marathon. We could add a DNS using an usual terminal command of Docker through the cmd command of Marathon, but then we will not be able to manage the apps very well. We could overwrite /etc/resolv.conf file with the configuration that we want when the container starts up, but this method is very ugly. How did I solve it? In a really easy way: The DNS has to be running always on the same server and we need to know the IP, so you can use the constraints of Marathon in order to indicate where the DNS (or DNSs to have HA) will be running. If you have your apps in production, you will not try to mix apps of several projects which will be pointing to different DNSs. If you are in the right case, you have to point the host server to the known IP of Mesos-DNS. Docker makes a copy of the /etc/resolv.conf file of the host server into the Docker container when no DNS information is provided. Now, we only need to launch our apps through Marathon indicating HOST as network option. Introduction
Elixir is a really awesome language which runs in the Erlang Virtual Machine (BEAM). So it takes advantage of all the concurrent and distribution features of Erlang by free.
In order to demonstrate it I have decided to develop a proof of concept (PoC) of a Publisher-Subscriber system only using Elixir. Coding
I will begin building a Publisher. This module will be based on GenServer. It will take care of subscriptions, unsubscriptions and notifications. But we have to remember that Elixir as pure functional programming language does not maintain a state, how will be able to know who is subscribed?
Elixir provides a module called Agent which is prepared for this kind of issues. I will create a SubscriptionManager based on Agent in order to track all the subscriptions. defmodule SubscriptionManager do def start_link do Agent.start_link(fn -> %{} end) end def start do Agent.start(fn -> %{} end) end def get_all(agent) do Agent.get(agent, fn x -> x end) end def get(agent, key) do Agent.get(agent, fn x -> Map.get(x, key) end) end def put(agent, key, value) do Agent.update(agent, fn x -> Map.put(x, key, value) end) end def delete(agent, key) do Agent.get_and_update(agent, fn x -> Map.pop(x, key) end) end end
We can also improve this module using ETS but let's do it other time ;).
Once that we have a module on charge of the subscriptions, we can develop the Publisher module:
defmodule Publisher do use GenServer # Server def start do {:ok, subscription_manager} = SubscriptionManager.start GenServer.start(Publisher, subscription_manager) end def handle_cast({:subscribe, name, pid}, subscription_manager) do SubscriptionManager.put(subscription_manager, name, pid) {:noreply, subscription_manager} end def handle_cast({:unsubscribe, name}, subscription_manager) do SubscriptionManager.delete(subscription_manager, name) {:noreply, subscription_manager} end def handle_cast({:notify, message}, subscription_manager) do SubscriptionManager.get_all(subscription_manager) |> Enum.map(fn {key, value} -> GenEvent.notify(value, message) end) {:noreply, subscription_manager} end # Client def subscribe(server, name, pid) do GenServer.cast(server, {:subscribe, name, pid}) end def unsubscribe(server, name) do GenServer.cast(server, {:unsubscribe, name}) end def notify(server, message) do GenServer.cast(server, {:notify, message}) IO.puts "I have published: '#{message}'" end end
Then, we only need to develop our Subscriber module. It will be based on GenEvent and it will handle the received events in the easier way that we know: Printing.
defmodule Subscriber do use GenEvent def start do {:ok, pid} = GenEvent.start([]) GenEvent.add_handler(pid, Subscriber, []) {:ok, pid} end def handle_event(message, state) do IO.puts "I have received: '#{message}'" {:ok, state} end end Testing
Erlang, and by extension Elixir, has the possibility of connecting Erlang Virtual Machines. I will use this capability within the same host but it will work with hosts that see each others.
I will run three BEAMs, one for the publisher and two for the subscribers.
Node 1: The Publisher
Open a console and type:
$ iex --sname node1 --cookie pubsub -S mix
Now that we have an IEX running type the following:
iex(node1@host)> {:ok, manager} = Publisher.start iex(node1@host)> :global.register_name('manager', manager)
I am registering the Publisher process globally using the name "manager" therefore any process from any connected BEAM will be able to find it.
Node 2: The Subscriber
Open another console and type:
iex --sname node2 --cookie pubsub -S mix
Now that we have an IEX running type the following:
iex(node2@host)> Node.connect :'node1@host' iex(node2@host)> manager = :global.whereis_name('manager') iex(node2@host)> {:ok, subscriber} = Subscriber.start iex(node2@host)> Publisher.subscribe(manager, 'subs_node2', subscriber)
Firstly we have to connect to the node1 and then using the :global module this process is able to subscribe to the Publisher that can be even in other host.
Node 3: The Subscriber
iex --sname node3 --cookie pubsub -S mix
And type in the IEX:
iex(node3@host)> Node.connect :'node1@host' iex(node3@host)> manager = :global.whereis_name('manager') iex(node3@host)> {:ok, subscriber} = Subscriber.start iex(node3@host)> Publisher.subscribe(manager, 'subs_node3', subscriber)
Publish a message:
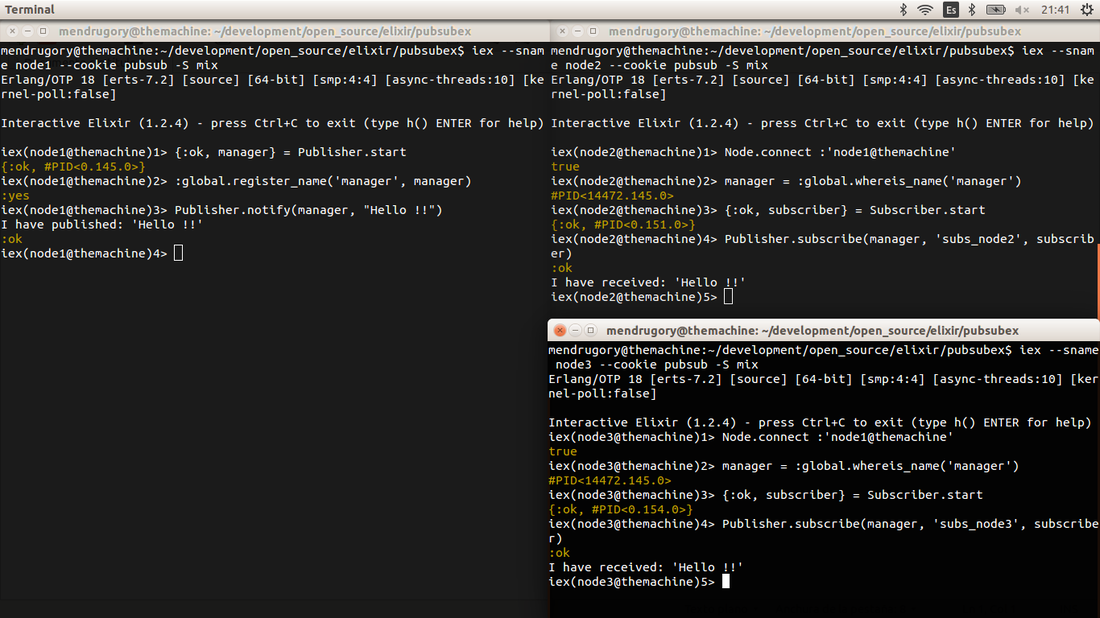
Using whatever IEX (node1, node2 or node3) type the following: iex> Publisher.notify(manager, "Hello !!")
The two subscriber will receive the sent message, "Hello !!" in this case.
Conclusion
As you have seen, it is really easy to code a distributed system using Elixir.
You can find the code in my github. |
about what?
I like the technology, specially the SW technologies related to Big Data, Cloud, Mobile, M2M and IoT.  Archives
January 2016
Categories
All
|
 RSS Feed
RSS Feed
