Real-time analytics is very trendy. Nowadays, everyone wants to analyze the data that they have, even if those data are not very useful, and they want the results as soon as possible, even if they can wait for those results.
One of the most powerful data sources are the social networks and inside this group, Twitter. Therefore I decided to build a system (as proof of concept) in order to analyze tweets related to BigData.
Firstable I decided that the app would be deployed in openshift. Openshift is a PaaS product from Red Hat and I like due to its flexibility. Python was the chosen language, Django the chosen framework and MongoDB the chosen data base.
If you want to interact with Twitter you will need to register your app in order to get the Twitter's credentials for your new app. So, I visited the Twitter Developers web and I registered my app, talkingbigdata:
One of the most powerful data sources are the social networks and inside this group, Twitter. Therefore I decided to build a system (as proof of concept) in order to analyze tweets related to BigData.
Firstable I decided that the app would be deployed in openshift. Openshift is a PaaS product from Red Hat and I like due to its flexibility. Python was the chosen language, Django the chosen framework and MongoDB the chosen data base.
If you want to interact with Twitter you will need to register your app in order to get the Twitter's credentials for your new app. So, I visited the Twitter Developers web and I registered my app, talkingbigdata:
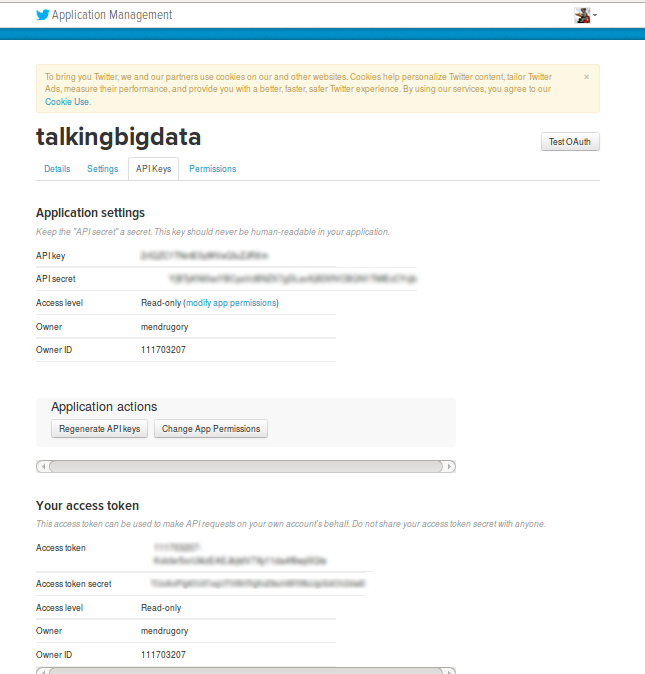
The most important part are:
- API key
- API secret
- Access token
- Access token secret
Once that we have registered the app and we have obtained the credentials, let's code.
The first part is connecting to the Twitter API Stream and for that purpose I utilized tweepy.
Authorization:
1: class TwitterAuth(object):
2: '''
3: class to manage the twitter authorization 4: '''
5: 6: def __init__(self): 7: self.auth = tweepy.OAuthHandler(secret.CONSUMER_KEY, secret.CONSUMER_SECRET) 8: self.auth.set_access_token(secret.ACCESS_TOKEN, secret.ACCESS_TOKEN_SECRET) 9: self.api = tweepy.API(self.auth) 10: 11: def get_auth(self): 12: return self.auth
13: 14: def get_api(self): 15: return self.api
Tweepy brings a very useful class, StreamListener(), which manages the Twitter's Stream. So I created CustomStreamListener class which inherits from StreamListener and it contains the common things and I also created MongoDBStreamListener class which inherits from CustomStreamListener and it will perform the specific things for MongoDB data base. In this way I have the structure in order to add other data bases or even other things.
Stream Listener:
1: class CustomStreamListener(tweepy.StreamListener):
2: '''
3: Custom class to manage the twitter streaming 4: '''
5: def __init__(self): 6: super(CustomStreamListener, self).__init__() 7: 8: def on_data(self, tweet): 9: pass 10: 11: 12: class MongoDBStreamListener(CustomStreamListener):
13: ''' class in order to manage the tweet and store into Mongo '''
14: 15: def __init__(self): 16: super(MongoDBStreamListener, self).__init__() 17: 18: def on_data(self, tweet): 19: super(MongoDBStreamListener, self).on_data(tweet) 20: json_tweet = json.loads(tweet) 21: doc = self.process_tweet(json_tweet) 22: MongoDBStreamListener.process_all_studies(doc) 23: 24: def on_status(self, status): 25: super(MongoDBStreamListener, self).on_status(status) 26: 27: def on_error(self, status_code): 28: '''
29: don't kill the stream although an error happened. 30: '''
31: super(MongoDBStreamListener, self).on_error(status_code) 32: 33: def on_timeout(self): 34: super(MongoDBStreamListener, self).on_timeout() 35: 36: def process_tweet(self, tweet): 37: doc = Tweet() 38: doc.created_at = tweet["created_at"]
39: doc.favorite_count = tweet["favorite_count"]
40: doc.favorited = tweet["favorited"]
41: doc.lang = tweet["lang"]
42: doc.retweet_count = tweet["retweet_count"]
43: doc.retweeted = tweet["retweeted"]
44: doc.source = tweet["source"]
45: doc.tweet_text = tweet["text"]
46: doc.filter_level = tweet["filter_level"]
47: doc.tweet_id = tweet["id"]
48: if tweet["coordinates"] is not None:
49: doc.longitude = tweet["coordinates"]["coordinates"][0]
50: doc.latitude = tweet["coordinates"]["coordinates"][1]
51: self.save_tweet(doc, tweet) 52: MongoDBStreamListener.delay() 53: return doc
54: 55: @staticmethod 56: def process_all_studies(tweet): 57: source_worker = Worker(SourceProcessor(TweetSource), tweet) 58: source_worker.start() 59: lang_worker = Worker(LanguageProcessor(TweetLanguage), tweet) 60: lang_worker.start() 61: 62: def save_tweet(self, doc, tweet): 63: if MONGODB_USER is None:
64: doc.save() When a tweet arrives, MongoDBStreamListener extracts the information from the tweet (it comes in JSON format) and puts it inside a Tweet object:
1: class Tweet(mongoengine.Document):
2: created_at = mongoengine.StringField(max_length=200) 3: tweet_id = mongoengine.IntField(default=-1)
4: tweet_text = mongoengine.StringField(max_length=500) 5: source = mongoengine.StringField(max_length=200) 6: retweet_count = mongoengine.IntField(default=0)
7: favorite_count = mongoengine.IntField(default=0)
8: lang = mongoengine.StringField(max_length=5) 9: favorited = mongoengine.BooleanField(default=False)
10: retweeted = mongoengine.BooleanField(default=False)
11: filter_level = mongoengine.StringField(max_length=60) 12: latitude = mongoengine.FloatField(default=None)
13: longitude = mongoengine.FloatField(default=None)
14: 15: def __repr__(self): 16: return str(Tweet.source.to_python('utf-8'))
The process_all_studies() method will calculate all the studies from the Tweet information. In this case the study of the languages and the study of the sources. For that, a Worker() is launched per each study. A worker needs a Tweet() and TweetProcessor() which needs a model class.
This strategy helps us in order to add more studies in the future.
Worker:
This strategy helps us in order to add more studies in the future.
Worker:
1: class Worker(multiprocessing.Process):
2: '''
3: The class which will generate an independant process in order to process the tweet for 4: a particular study. 5: '''
6: 7: def __init__(self, tweet_processor, tweet): 8: '''
9: Child class of processor. It needs a TweetProcessor class in order to be launch in a new process. 10: '''
11: super(Worker, self).__init__(target=tweet_processor.run, args=(tweet,)) Processor of Tweets:
1: class TweetProcessor(object):
2: '''
3: Base class in order to process a tweet 4: '''
5: 6: def __init__(self, model): 7: self.document = None 8: self.model = model 9: 10: def run(self, tweet): 11: '''
12: The function which will be launch in the process 13: '''
14: self.process(tweet) 15: self.save() 16: 17: def process(self, tweet): 18: '''
19: Main method of the class. It will have to be implemented by the child classes. 20: '''
21: filter_key = self.get_the_key(tweet) 22: self.document = self.get_the_document(filter_key) 23: 24: def get_the_document(self, filter_key): 25: '''
26: Retrieve the document 27: '''
28: query = self.model.objects(filter_key=filter_key).limit(1) 29: if len(query) == 0:
30: document = self.model() 31: else:
32: document = query[0] 33: return document
34: 35: def save(self): 36: '''
37: Save into database the document. 38: '''
39: self.document.save() 40: 41: def get_the_key(self, tweet): 42: '''
43: Obtain the key from the tweet which will be used as filter 44: '''
45: pass 46: 47: def update_value(self): 48: '''
49: Update method for the main value 50: '''
51: pass 52: 53: 54: class SourceProcessor(TweetProcessor):
55: '''
56: Class to process the source of the tweet 57: '''
58: 59: def __init__(self, tweet): 60: super(SourceProcessor, self).__init__(tweet) 61: 62: def process(self, tweet): 63: super(SourceProcessor, self).process(tweet) 64: if self.document.filter_key is None:
65: self.document.filter_key = self.get_the_source(tweet.source) 66: self.document.source = tweet.source 67: self.document.url = self.get_url(tweet.source) 68: self.document.last_change = tweet.created_at 69: self.document.count += 1 70: self.update_value() 71: 72: def get_the_key(self, tweet): 73: '''
74: Get the key 75: '''
76: source = tweet.source 77: return self.get_the_source(source)
78: 79: def get_the_source(self, source): 80: '''
81: Get the source from the tweet 82: '''
83: key = source.split(">")[1].split("<")[0].strip()
84: return key.encode("utf-8")
85: 86: def update_value(self): 87: '''
88: Update method for the main value 89: '''
90: self.document.value += 1 91: 92: def get_url(self, source): 93: key = source.split("rel=")[0].split("href=")[1].split("\"")
94: return key[1].encode("utf-8")
95: 96: 97: class LanguageProcessor(TweetProcessor):
98: '''
99: Class to process the language of the tweet 100: '''
101: 102: def __init__(self, tweet): 103: super(LanguageProcessor, self).__init__(tweet) 104: 105: def process(self, tweet): 106: super(LanguageProcessor, self).process(tweet) 107: if self.document.filter_key is None:
108: self.document.filter_key = self.get_the_language(tweet.lang) 109: self.document.language = tweet.source 110: self.document.last_change = tweet.created_at 111: self.document.count += 1 112: self.update_value() 113: 114: def get_the_key(self, tweet): 115: '''
116: Get the key 117: '''
118: key = tweet.lang 119: return self.get_the_language(key)
120: 121: def get_the_language(self, lang): 122: '''
123: Get the Language from the tweet 124: '''
125: language = lang.encode("utf-8")
126: return language
127: 128: def update_value(self): 129: '''
130: Update method for the main value 131: '''
132: self.document.value += 1 As you can see, the current study is to count the number of languages and sources.
Model (for MongoDB):
Model (for MongoDB):
1: class TweetSource(mongoengine.Document):
2: source = mongoengine.StringField(max_length=200, default=None)
3: filter_key = mongoengine.StringField(max_length=200, default=None)
4: count = mongoengine.IntField(default=0)
5: last_change = mongoengine.StringField() 6: value = mongoengine.IntField(default=0)
7: url = mongoengine.StringField(max_length=200, default="http://www.twitter.com")
8: 9: meta = { 10: 'indexes': ['filter_key', ('filter_key', '-value')],
11: 'ordering': ['-value']
12: } 13: 14: 15: class TweetLanguage(mongoengine.Document):
16: language = mongoengine.StringField(max_length=209, default=None)
17: filter_key = mongoengine.StringField(max_length=209, default=None)
18: count = mongoengine.IntField(default=0)
19: last_change = mongoengine.StringField() 20: value = mongoengine.IntField(default=0)
21: 22: meta = { 23: 'indexes': ['filter_key', ('filter_key', '-value')],
24: 'ordering': ['-value']
25: } After having all the structure we have to connect to Twitter:
1: class TwitterStreaming(object):
2: '''
3: Twitter Streaming 4: '''
5: 6: def __init__(self, stream_listener=MongoDBStreamListener, auth=TwitterAuth): 7: self.twitter_auth = auth() 8: self.stream_listener = stream_listener 9: 10: 11: def run(self, tracking=None, locations=None): 12: '''
13: Run the streaming 14: 15: tracking: list of topics 16: '''
17: 18: sapi = tweepy.streaming.Stream(self.twitter_auth.get_auth(), self.stream_listener()) 19: sapi.filter(track=tracking, locations=[]) Conclusion:
Openshift is a very good option when you want to try a PaaS for free. The only problem is that openshift stops your server if you don't receive a request for a long time, but I need to remember that my account is free.
Python was a very good option because it is easy and it has a lot of libraries which help you a lot, for example tweepy.
MongoDB was another good option because is so simple to use when your data does not have relations. Besides, the Twitter's data come in json that is the format that MongoDB uses for its Documents.
Django is a very powerful framework but it was not key for this project. Moreover, Django-ORM does not have support for MongoDB and I missed a lot of things that Django gives you for free; hence, I had to work MongoEngine which is a very good library and it is like working with Django-ORM or SQLAlchemy. Therefore, after all, I would have used Flask for this project.
This project is in github.

 RSS Feed
RSS Feed
